Evolutionary Algorithm¶
stk includes an evolutionary algorithm which
can be used to evolve molecules that fulfil user defined design criteria.
The evolutionary algorithm can be run from the command line using:
$ python -m stk.ea input_file.py
The input file is a simple python script which defines the calculators the evolutionary algorithm should use, as well as some optional parameters.
The evolutionary algorithm automatically works with any molecules that stk
uses, both BuildingBlock and ConstructedMolecule objects.
Take for example the following input file which runs the EA on polymers and selects building blocks which have the most atoms.
# #####################################################################
# Imports.
# #####################################################################
import stk
import logging
# #####################################################################
# Pick a random seed.
# #####################################################################
random_seed = 12
# #####################################################################
# Run GA serially.
# #####################################################################
num_processes = 1
# #####################################################################
# Set logging level.
# #####################################################################
logging_level = logging.DEBUG
# #####################################################################
# Initial population.
# #####################################################################
carbon = 'C'
building_blocks = [
stk.BuildingBlock(f'[Br]{carbon*i}[Br]', ['bromine'])
for i in range(2, 27)
]
topology_graphs = [
stk.polymer.Linear('A', 3),
stk.polymer.Linear('A', 6),
stk.polymer.Linear('A', 12)
]
population = stk.EAPopulation.init_random(
building_blocks=[building_blocks],
topology_graphs=topology_graphs,
size=25,
use_cache=True,
random_seed=random_seed
)
# #####################################################################
# Selector for selecting the next generation.
# #####################################################################
generation_selector = stk.SelectorSequence(
stk.Fittest(num_batches=3, duplicates=False),
stk.Roulette(
num_batches=22,
duplicates=False,
random_seed=random_seed
)
)
# #####################################################################
# Selector for selecting parents.
# #####################################################################
crossover_selector = stk.AboveAverage(num_batches=5, batch_size=2)
# #####################################################################
# Selector for selecting molecules for mutation.
# #####################################################################
mutation_selector = stk.SelectorFunnel(
stk.AboveAverage(num_batches=10, duplicates=False),
stk.Roulette(num_batches=5, random_seed=random_seed)
)
# #####################################################################
# Crosser.
# #####################################################################
crosser = stk.Jumble(
num_offspring_building_blocks=3,
random_seed=random_seed
)
# #####################################################################
# Mutator.
# #####################################################################
mutator = stk.RandomMutation(
stk.RandomTopologyGraph(topology_graphs, random_seed=random_seed),
stk.RandomBuildingBlock(
building_blocks=building_blocks,
key=lambda mol: True,
random_seed=random_seed
),
stk.SimilarBuildingBlock(
building_blocks=building_blocks,
key=lambda mol: True,
duplicate_building_blocks=False,
random_seed=random_seed
),
random_seed=random_seed
)
# #####################################################################
# Optimizer.
# #####################################################################
optimizer = stk.NullOptimizer(use_cache=True)
# #####################################################################
# Fitness calculator.
# #####################################################################
def num_atoms(mol):
return len(mol.atoms)
fitness_calculator = stk.PropertyVector(num_atoms)
# #####################################################################
# Fitness normalizer.
# #####################################################################
# The PropertyVector fitness calculator will set the fitness as
# [n_atoms] use the Sum() fitness normalizer to convert the fitness to
# just n_atoms^0.5. The sqrt is because we use the Power normalizer.
fitness_normalizer = stk.NormalizerSequence(
stk.Power(0.5),
stk.Sum()
)
# #####################################################################
# Exit condition.
# #####################################################################
terminator = stk.NumGenerations(25)
# #####################################################################
# Make plotters.
# #####################################################################
plotters = [
stk.ProgressPlotter(
filename='fitness_plot',
property_fn=lambda mol: mol.fitness,
y_label='Fitness',
),
stk.ProgressPlotter(
filename='atom_number_plot',
property_fn=lambda mol: len(mol.atoms),
y_label='Number of Atoms',
)
]
stk.SelectionPlotter(
filename='generational_selection',
selector=generation_selector,
molecule_label=lambda mol: f'{mol.id} - {mol.fitness}',
x_label='Molecule: id - fitness value'
)
stk.SelectionPlotter(
filename='crossover_selection',
selector=crossover_selector,
molecule_label=lambda mol: f'{mol.id} - {mol.fitness}',
x_label='Molecule: id - fitness value'
)
stk.SelectionPlotter(
filename='mutation_selection',
selector=mutation_selector,
molecule_label=lambda mol: f'{mol.id} - {mol.fitness}',
x_label='Molecule: id - fitness value'
)
Running the evolutionary algorithm with this input file:
$ python -m stk.ea big_monomers.py
will produce the following directory structure:
|-- stk_ea_runs
| |-- 0
| | |-- scratch
| | | |-- atom_number_plot.png
| | | |-- atom_number_plot.csv
| | | |-- fitness_plot.png
| | | |-- fitness_plot.csv
| | | |-- generational_selection_1.png
| | | |-- crossover_selection_1.png
| | | |-- mutation_selection_1.png
| | | |-- progress.log
| | | |-- ...
| | |
| | |-- final_pop
| | | |-- 150.mol
| | | |-- 2160.mol
| | | |-- 9471.mol
| | | |-- ...
| | |
| | |-- big_monomers.py
| | |-- database.json
| | |-- progress.json
| | |-- errors.log
| | |-- output.tgz
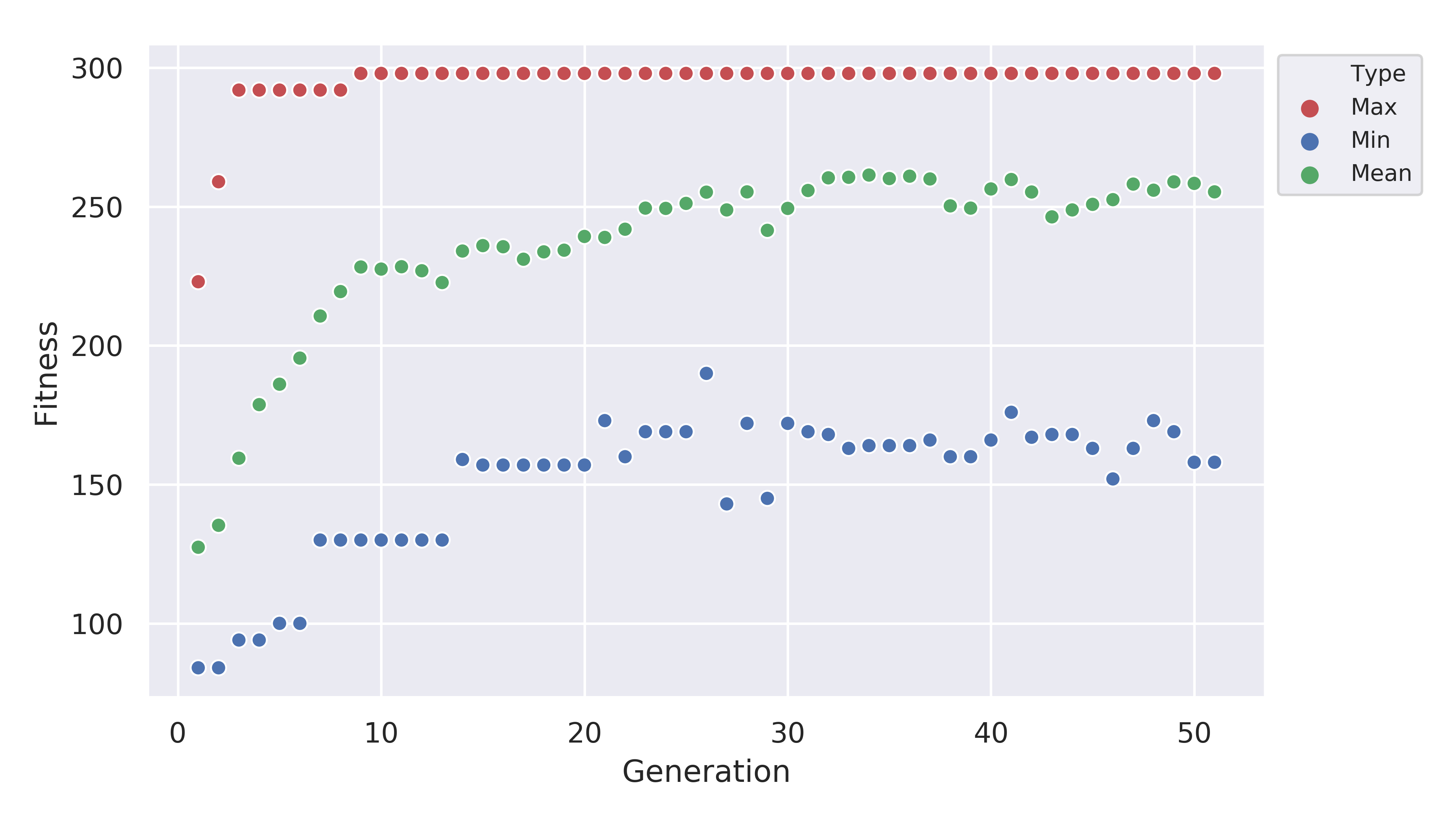
A glance at the evolutionary progress plot in
scratch/fitness_plot.png will show us how well our EA did.
Running the evolutionary algorithm again:
$ python -m stk.ea big_monomers.py
will add a second subfolder with the same structure:
|-- stk_ea_runs
| |-- 0
| | |-- counters
| | | |-- gen_1_crossover_counter.png
| | | |-- gen_1_mutation_counter.png
| | | |-- gen_1_selection_counter.png
| | | |-- ...
| | |
| | |-- final_pop
| | | |-- 150.mol
| | | |-- 2160.mol
| | | |-- 9471.mol
| | | |-- ...
| | |
| | |-- big_monomers.py
| | |-- database.json
| | |-- progress.json
| | |-- errors.log
| | |-- progress.log
| | |-- epp.png
| | |-- epp.csv
| | |-- output.tgz
|
| |-- 1
| | |-- scratch
| | | |-- atom_number_plot.png
| | | |-- atom_number_plot.csv
| | | |-- fitness_plot.png
| | | |-- fitness_plot.csv
| | | |-- generational_selection_1.png
| | | |-- crossover_selection_1.png
| | | |-- mutation_selection_1.png
| | | |-- progress.log
| | | |-- ...
| | |
| | |-- final_pop
| | | |-- 150.mol
| | | |-- 2160.mol
| | | |-- 9471.mol
| | | |-- ...
| | |
| | |-- big_monomers.py
| | |-- database.json
| | |-- progress.json
| | |-- errors.log
| | |-- output.tgz
The evolutionary algorithm can also be run multiple times in a row:
$ python -m stk.ea -l 5 big_monomers.py
which will run the EA 5 separate times adding 5 more subfolders to the directory structure:
|-- stk_ea_runs
| |-- 0
| | |-- ...
| |
| |-- 1
| | |-- ...
| |
| |-- 2
| | |-- ...
| |
| |-- 3
| | |-- ...
| |
| |-- 4
| | |-- ...
| |
| |-- 5
| | |-- ...
| |
| |-- 6
|-- ...
The benefit of using the -l option is that the molecular cache is
not reset between each run. This means that a molecule which was constructed,
optimized and had its fitness value calculated in the first run will
not need to be re-constructed, re-optimized or have fitness value
re-calculated in any of the subsequent runs. The cached version
of the molecule will be used.
However, the molecular cache be pre-loaded even when the -l option is
not used, simply load the molecules in the input file.
# some input_file.py
# There is no need to save this population into a variable.
# It is enough to load the molecules to place them into the cache.
stk.Population.load('dumped_molecules.json',
stk.Molecule.from_dict)
The output of a single EA consists of a number of files and
directories. The scratch directory holds any files created during
the EA run. For example, the .png files showing
how frequently a member of the population was selected for mutation,
crossover and generational selection. For example, this is a
mutation counter
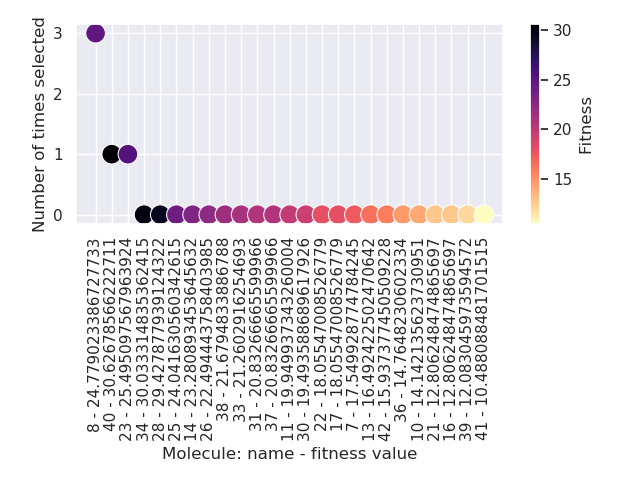
It shows that molecule 8 was selected three times for mutation, while molecules
40, 23` were selected once. The
remaining molecules were not mutated in that generation.
The final_pop directory holds the .mol files holding the
structures of the last generation of molecules.
The file big_monomers.py is a copy of the input file. The database.json
file is a population dump file which holds every molecule produced by
the EA during the run. progress.json is also a population dump file.
This population holds
every generation of the EA as a subpopulation. This is quite useful
if you want to analyse the output of the EA generation-wise.
errors.log is a file which contains every exception and its
traceback encountered by the EA during its run.
progress.log is a file which lists which molecules make up each
generation, and their respective fitness values.
output.tgz is a tarred and compressed copy of the output folder for
the run.
This means if you want to share you entire run output you can just
share this file.
Finally, when running the EA the progress will be printed into stderr. The message should be relatively straightforward, such as
======================================================================
17:42:20 - INFO - stk.ea.mutation - Using random_bb.
======================================================================
which shows the time, the level of the message which can be, in order of priority DEBUG, INFO, WARNING, ERROR or CRITICAL, the module where the message originated and finally the message itself.
Evolutionary algorithm input file variables.¶
This section lists the variables that need to be defined in the EA input file, along with a description of each variable.
population-EAPopulation- mandatory - The initial population of the EA.optimizer-Optimizer- mandatory - The optimizer used to optimize the molecules created by the EA.fitness_calculator-FitnessCalculator- mandatory - The fitness calculator used to calculate fitness of molecules.crosser-Crosser- mandatory - The crosser used to carry out crossover operations.mutator-Mutator- mandatory - The mutator used to carry out mutation operations.generation_selector-Selector- mandatory - The selector used to select the next generation.batch_sizemust be1.mutation_selector-Selector- mandatory - The selector used to select molecules to mutate.batch_sizemust be1.crossover_selector-Selector- mandatory - The selector used to select molecules for crossover.terminator-Terminator- mandatory - The terminator which determines if the EA has satisfied its exit condition.fitness_normalizer-FitnessNormalizer- optional, default =NullFitnessNormalizer()- The fitness normalizer which normalizes fitness values each generation.num_processes-int- optional, default =psutil.cpu_count()- The number of CPU cores the EA should use.plotters-listofPlotter- optional, default =[]- Plotters which are used to plot graphs at the end of the EA.log_file-bool- optional, default =True- Toggles whether a log file which lists which molecules are present in each generation should be made.database_dump-bool- optional, default =True- Toggles whether aPopulationJSON file should be made at the end of the EA run. It will hold every molecule made by the EA.progress_dump-bool- optional, default =True- Toggles whether aPopulationJSON file should be made at the end of the EA run. It will hold every generation of the EA as a separate subpopulation.debug_dumps-bool- optional, default =False- IfTruea database and progress dump is made after every generation rather than just the end. This is nice for debugging but can seriously slow down the EA.tar_output-bool- optional, default =False- IfTruethen a compressed tar archive of the output folder will be made.logging_level-int- optional, default =logging.INFO- Sets the logging level in the EA.